
TIM HAYES
Associate Professor of Quantitative Psychology
Florida International University
My academic research addresses three main goals: (1) Evaluating, developing, and extending statistical methods, particularly methods for addressing missing data and other sources of parameter bias in structural equation models, (2) Clearly and accessibly disseminating these methodological advances to a broad audience that includes both quantitative and substantive researchers, and (3) Applying quantitative methods in the service of addressing substantive research questions. My interests fall at the intersection of Structural Equation Modeling (SEM), Multilevel Modeling (MLM), and Missing Data Analysis.
Recent Projects
Simply calculating ΔR-squared as the difference in R-squared values between a full model that includes all variables and a reduced model that excludes some target variable(s) of interest can yield inaccurate results if the set of overidentifying constraints implied by a full latent variable model depend on the variables to be excluded, or if the plausibility of the MAR assumption used to justify FIML estimation hinges on their inclusion. A recent paper bridging my interests in latent variable regression methods and missing data analysis discusses the potential pitfalls of two intuitive methods for calculating ΔR-squared in SEMs with latent variables and missing data that researchers might be likely to try and proposes two straightforward, easy-to-implement alternative approaches to this task, verifying their accuracy in a focused simulation study.
R-squared Change in SEMs with Latent Variables and/or Missing Data

Factor Score Regression in Connected Measurement Models featuring Correlated Uniquenesses and Cross-Loading Indicators
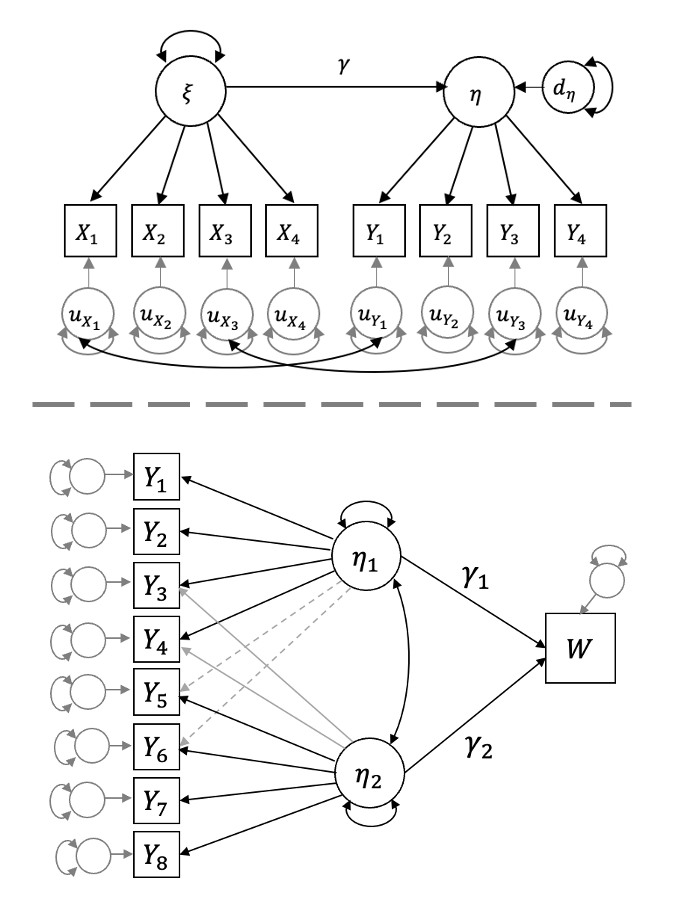
SEM is widely recognized as a gold standard approach that allows researchers to purge error variation (noise) from a set of observed measures in order to more accurately model the true score relationships among constructs in a set of simultaneous latent variable regressions. Yet, SEM’s large sample size requirements make it unfeasible in many practical contexts. Rather than falling back on observed variable regressions that ignore measurement error completely, if one’s sample size is not large enough to estimate all latent variables in a larger model simultaneously but is sufficiently large to estimate each individual latent variable separately, then one might adopt a two-step approach to latent variable regression modeling. First, one can extract factor score estimates from each separately estimated factor model. Next, these estimates can be used in place of participants’ observed scores as input in a subsequent regression or path analysis. To mitigate potential bias due to factor score indeterminacy, a set of analytic corrections may be applied to the variance-covariance matrix of these factor scores prior to estimating the regression model of interest (see Croon, 2002).
Extracting factor score estimates on a factor-by-factor basis is only possible when the factors adhere to perfect simple structure with conditionally independent residuals, however. To extend this approach to more realistic scenarios in which some items in a scale inadvertently tap multiple constructs (as would occur, e.g., if a question in a depression questionnaire was phrased in a manner that also invoked related constructs such as loneliness or social isolation), I rederived Croon’s (2002) bias corrected factor score regression (FSR) method in a general manner applicable to measurement structures connected by correlated residuals (Hayes & Usami, 2020a) and cross-loadings (Hayes & Usami, 2020b). The concepts discussed in this work have been cited and incorporated into the general structural after measurement (SAM) approach proposed by Rosseel and Loh (2022) and have been implemented in the corresponding sam() function in lavaan.
Projects
Current projects include:
(1) Developing novel rescaling approaches to obtaining cluster level probabilities and odds in multilevel models for binary outcomes.
(2) Using random forests to identify missing data auxiliary variables.
Write me an email at thayes@fiu.edu
Contact